However, as the predictive accuracy of ML models is getting better, the explainability of such models is seemingly getting weaker. Their intricate and obscure inner structure forces us more often than not to treat them as “black-boxes”, that is, getting their predictions in a no-questions-asked policy. Common “black-boxes” are Artificial Neural Networks (ANNs), ensemble methods. However seemingly interpretable models can be rendered unexplainable, like Decision Trees for instance when they have a big depth.
However, in this manner intellectual property issues arise, since organizations will not want to disclose any information about the details of their model. Therefore, from the wide range of interpretability methods, the model-agnostic approaches (i.e. methods that are oblivious of the model’s details) are deemed to be appropriate for this purpose.
Besides explaining the predictions of a black-box model, interpretability can also provide us with insight about erroneous behavior of our models, which may be caused by undesired patterns in our data. We will examine an example, where interpretability helps us identify gender bias in our data, using a model-agnostic method, which utilizes surrogate models and Shapley values.
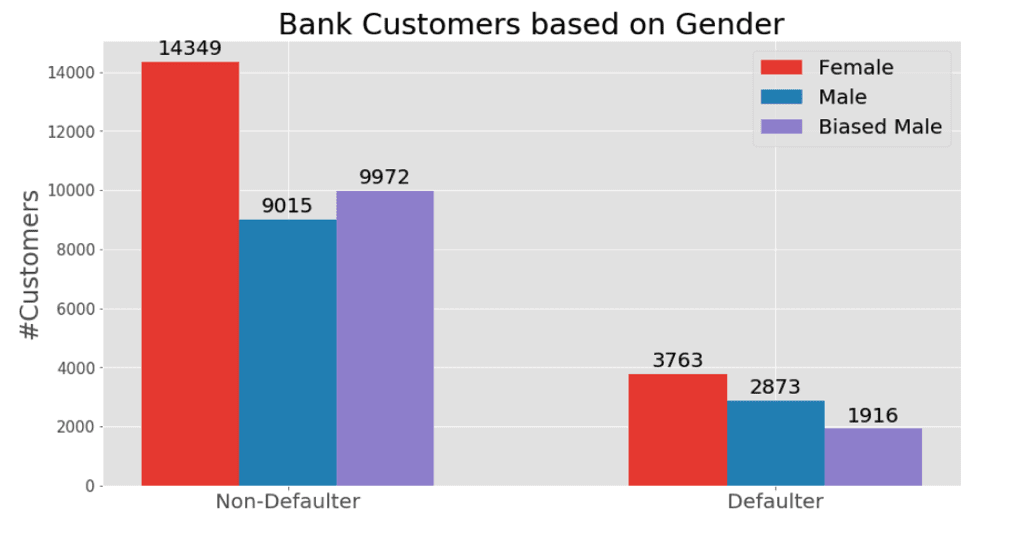
We use the “Default of Credit Card Clients Dataset”, which contains information (demographic factors, credit data, history of payment, and bill statements) about 30,000 credit card clients in Taiwan from April 2005 to September 2005. The target of the models in our examples is to identify the defaulters (i.e. bank customers, who will not pay the next payment of their credit card).
In the “Default of Credit Card Clients Dataset”, 43% of the defaulters are male and 57% are female. This does not consist in a biased dataset, since the non-defaulters have a similar distribution (39% and 61% respectively).
First, we examine a male customer (ID: 802) for whom the model predicted falsely that he will not default (i.e. false negative prediction) and then a female customer (ID: 319) for whom the model falsely predicted that she will default (i.e. false positive).
These two customers are very similar as the table below indicates: they both delayed the payments of September, August and July, and paid the payments of June, May and April.
Examining the explanation of the male customer, we can see that the 4-month delay of the last payment (September, 2005), had a negative impact of 28%, meaning that it contributed towards predicting that he will default. However, the gender and repayment status of April and May, as well as the amount of bill statement for September and May, had a positive impact, and resulted in classifying falsely the customer to the non-defaulters.
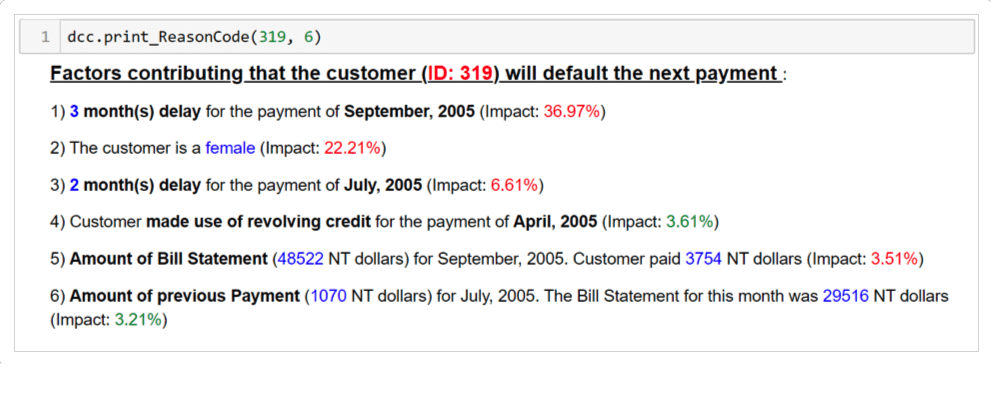
For the female customer, the 3-month delay also contributed negatively, but in a greater percentage compared to the male customer (37%). The gender also had a negative impact with 22%. Moreover, the model also considered important, the 2-month delay for the payment of July, whereas in the male customer, who had also the same delay, this was not deemed as important.
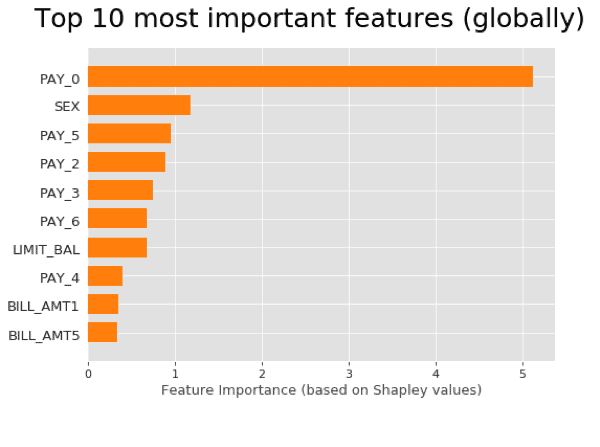
Global explanations also ascertain the gender bias, since the gender feature is the second overall most important feature for the model.
We repeat the experiments by removing the gender feature from the dataset. Now, the male customer is correctly predicted as a defaulter and the explanations make a bit more sense: the delay of the last payment (September) has a great impact of 49%, as well as the delays of the other two payments.
However, the model still falsely predicted that the female customer will default. Again, the delay of the last payment is the most important factor. We could argue that the model is still more harsh on this customer: although she paid a small amount for the payment of May (863 NT dollars), the model deemed it with a negative factor of 8%, whereas in the male case, the zero payment for April had only a negative impact of 4%. This should alarm us to examine for an unrepresented sample of male defaulters in our dataset and stimulate us to fix our data.
It is evident, that the explanations helped us identify bias in the data, as well as to pinpoint unintended decision patterns of our black-box model. Moreover, even when the gender feature was removed from the training data, the explanations assisted us in discovering bias proxies, meaning encoded (gender) bias across other features. This could lead us to the decision to acknowledge the bias in our data and motivates as to get a better sample of defaulters.
If the dataset contains real people, it is important to ensure that the model does discriminate against one group over others. Explanations facilitate us detect bias and motivate us to fix our data.