Is Twitter biased against BIPOC?
Maybe it’s not what you
think it is.




The controversy
Twitter was in the headlines recently for apparent racial bias in the photo preview of some tweets. More specifically, Twitter’s machine learning algorithm that selects which part of an image to show in a photo preview favors showing the faces of white people over black people. For example the following tweet, contains an image of Mitch McConnell (white male) and Barack Obama (black male) twice, but Twitter selects Mitch McConnell both times in the tweet’s preview photo.
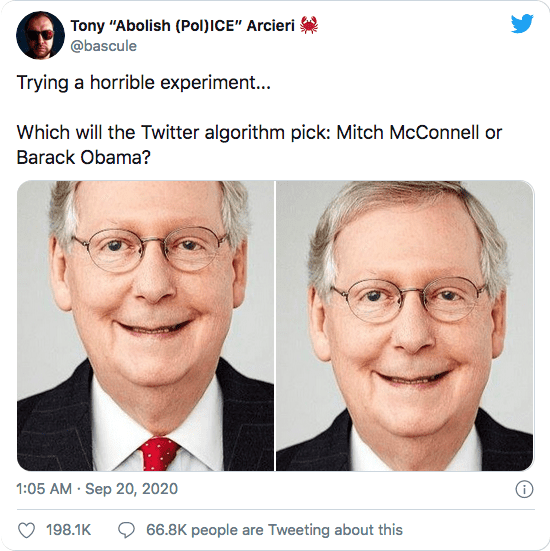
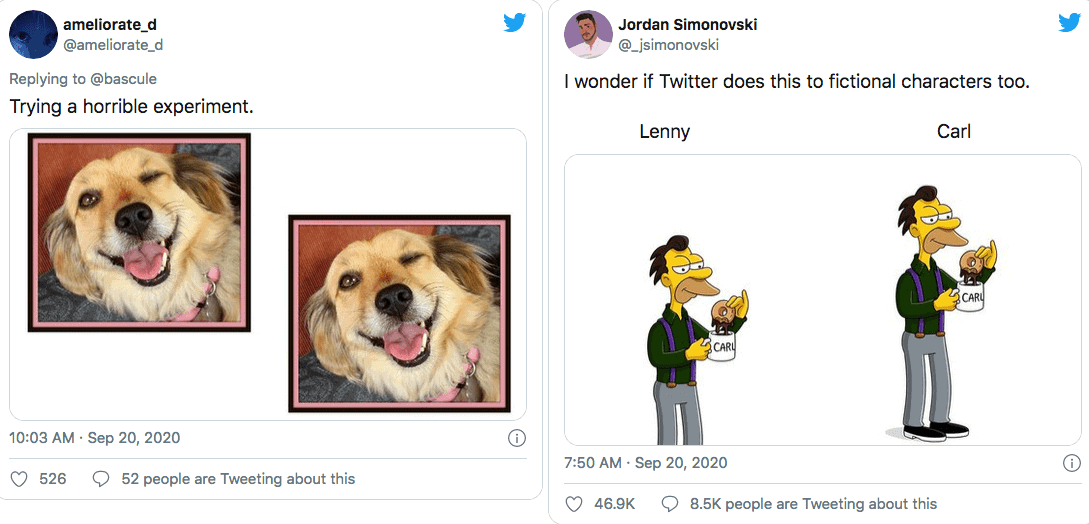
This tweet went viral with (currently) 81K retweets, almost 200K likes and was covered in articles by BBC and CNN. It also got the attention of many users who posted different configurations of images with black and white people and trying to verify themselves whether there is truly bias in Twitter’s preview selection model. Some even tried posting images with white and black dogs as well as cartoon characters.
Twitter’s official reply was: “We tested for bias before shipping the model & didn’t find evidence of racial or gender bias in our testing. But it’s clear that we’ve got more analysis to do. We’ll continue to share what we learn, what actions we take, & will open source it so others can review and replicate.”

Fairness evaluation
In code4thought, we are deeply concerned with bias and discrimination in algorithmic systems, especially when these systems can crucially affect real people. So we did our own testing with our fairness and transparency service called iQ4AI and we investigated if Twitter’s model is truly bias-free as Twitter’s official reply suggested.
In order to have a more systematic approach, we used a specialized dataset containing images of faces of different racial groups, which is balanced for all groups. To keep things simple we used only adult black and white males for our experiments and we constructed a new dataset containing combined photos — collages — of adult black males at the top, white adult males in the bottom and a white background between them. Our new dataset contained 4,009 pictures of black and white adult males, which we uploaded in an account on Twitter called @bias_tester. Finally, we manually labeled the preview photo of each tweet as ‘Black male’ if Twitter’s underlying model selected the black male, otherwise we labeled it as ‘White male’.
Using code4thought’s iQ4AI service on the new labeled dataset containing the 4,009 collage-photos and the preview label (‘Black male’, ’White male’), we examined Twitter’s model on fairness and transparency.
The metric we choose to measure fairness is Disparate Impact Ratio (DIR),which basically measures how differently the model behaves across different groups of people — in our case black and white adult males. More specifically it is the proportion of individuals that receive a positive outcome for two groups.
If there is great disparity in the model’s outcome for each group, then we can claim that there might be bias in the model. According to “4–5ths rule” by the U.S. Equal Employment Opportunity Commission (EEOC), any value of DIR below 80% can be regarded as evidence of adverse impact. Since DIR is a fraction and the denominator might be larger than the numerator, we consider an acceptable range of DIR from 80% to 120%.
Twitter allows its users to upload a certain amount of tweets per day, so we sent batches of 300 tweets of our collages every 3 hours. After each batch was uploaded, we manually measured the number of black and white males in Twitter’s preview photo and sent this data to our iQ4AI platform.
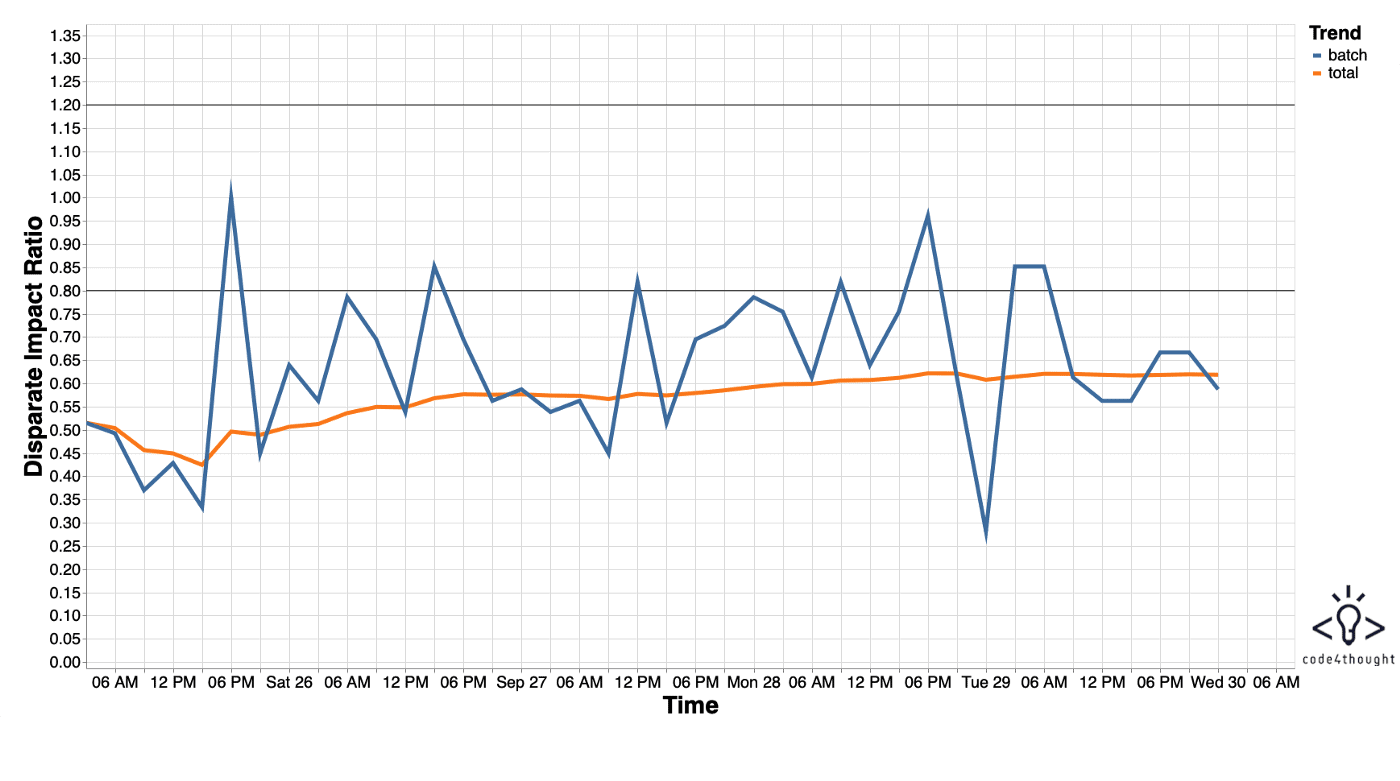
After all batches were sent, the total DIR was 0.61, which is much less than the accepted threshold. This analysis suggests that Twitter’s preview photo selection model is more likely to choose a white male than a black male. We can observe that, while some batches of data (blue line) were compliant, the total DIR (orange line) was continuously not compliant, which is an indication of bias towards black males.
Using explanations to verify bias
We would like to get a sense of how the underlying model “thinks” and try to understand its decision process, in order to find reasoning for the discovered bias of the fairness evaluation. We modified our existing dataset by using the individual images of the same black and white adult males from the collages, and labeled them with 1 if the photo was selected in the preview, otherwise we labeled them with 0. We used iQ4AI model-agnostic explainer , which utilizes surrogate models (i.e. models that try to mimic the original model) and Shapley values, in order to explain the predictions of the Twitter’s preview selection model, even without having direct access to it (more info about our method can be found in this corresponding paper).
Clearly the size of our dataset (8,018 pictures) is not enough to give us information in a confident way about how Twitter’s internal model makes its predictions, however it can give us already some insights.
Below are some examples of explanations from our dataset. The green and red pixels in the grayscale image demonstrate positive and negative contributions correspondingly towards selecting the image as the preview photo.


Looking at the first two examples above, where the model selected the white male, we could say that pixels on the cheeks with a darker tone (whether because of the black skin or because of the shade) as well as the eyes of the black males contribute negatively and conclude that the model is biased against dark skin pixels.
However, we can not confirm this assertion by looking at the next two examples, where the model selected the black male. Moreover, some explanations show that pixels in the background also are contributive, which makes us wonder if any facial characteristic plays an important role at all in the model’s selection process.

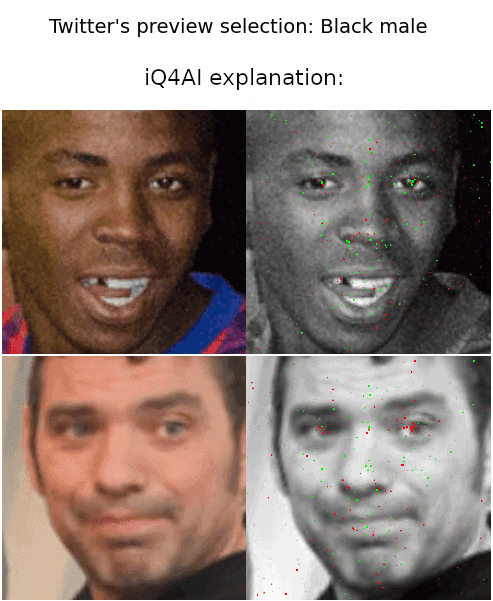
Since we do not know what is the goal of Twitter’s preview selection model (e.g. facial recognition), it is difficult to understand the explanations. On a first glance, we might observe that the model tries to identify facial characteristics such as the eyes, nose and cheeks.
This unclear behavior led us to analyze a bit further our data and look for other attributes of the images which are not correlated with the facial features of the person in the image. So we measured the sharpness and contrast of the photos and using iQ4AI explainer again we checked whether either one of them played an important role in the predictions. The following scatter plot shows how sharpness plays an important role in the model’s decision process.
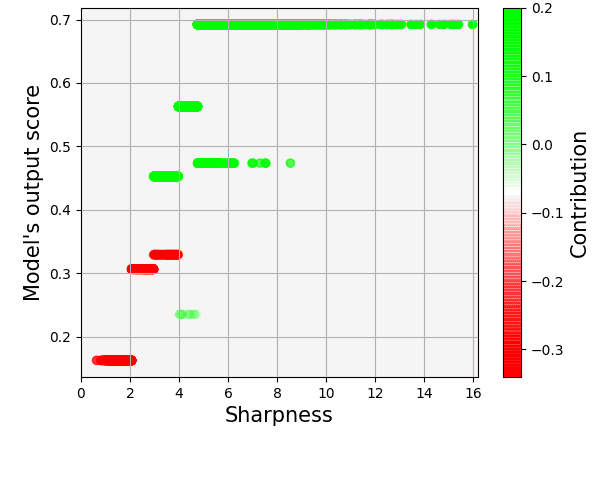
The vertical axis depicts the output of the (surrogate) model and the horizontal axis the sharpness of each image. We can observe that for less sharp photos (i.e. sharpness less than 3) the contribution is negative (red color) leading to a low model output score, while for photos with a higher value of sharpness (i.e. more than 5) the contribution is positive (green color) and the output score is higher.
In fact, we measured the sharpness of the two pictures shown in the tweet that started this whole debate, and we found that McConnell’s photo was sharper than Obama’s — the exact sharpness values were 5.65 and 3.54 correspondingly. As for the contrast of the photos, there was no strong correlation with the model’s predictions and as a result it did not play an important role in the model.
Bottomline: is there any discrimination in Twitter’s model?
Our analysis on the deducted explanations suggests that the model does not depend on any facial feature of the people inside an image, rather than on the total image quality, and probably on the sharpness of an image. Again, this conclusion derives from analysing a small dataset and we can not confidently assert that Twitter’s model has this behaviour overall.
If we assume that our analysis is valid for larger datasets, then there is an important question that must be answered: Does the fact that Twitter’s model is not directly discriminatory, since it does not rely on racial or facial features, means that there is no ethical issue and that this controversy should end?
In code4thought we firmly believe that any trace of unfairness towards specific groups of people in an algorithmic process should be addressed and then solved, even if the process does not utilise any direct discriminatory procedures. We look forward to seeing Twitter’s further reactions and analysis on the issue in question and we hope that we did our small contribution to the public discourse on how we can make technology more fair and responsible.