Software Maintainability
in the service of Security
by Design


When we refer to software quality, we tend to think that the focus is drawn to the functionality of a software system and the reassurance that it does what it is expected to do. However, according to the ISO 25010 there are 8 different quality characteristics to describe software quality, more specifically Functional suitability, Performance efficiency, Compatibility, Usability, Reliability, Security, Maintainability and Portability.
The software quality characteristic that can support and facilitate all the rest is Maintainability. Maintainability refers to the ability to make changes faster in software and with less risk to break the existing functionality or introduce new bugs. How fast changes in software can be implemented is a trait that can be directly associated with Security, as the time window until a security issue is mitigated should be the smallest possible in order to minimize the impact of the attack and avoid greater financial or other costs.
Time matters
When a security incident occurs it is of great significance to provide a fix as fast and safely as possible, avoiding sloppiness in the sake of urgency.
In our practice at code4thought we use SIG’s 5-star rating model in order to measure software Maintainability, which has proved that time-to-market of a highly-maintainable 4-star system can be up to 3,8 times faster than a less maintainable 2-star one¹.
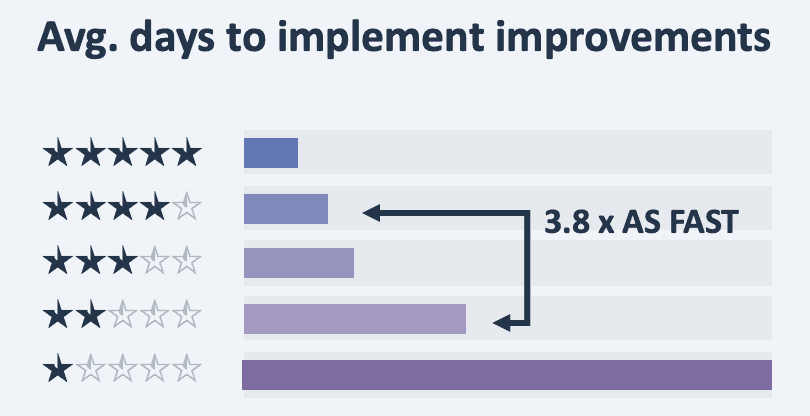
Maintainable code gives you the advantage of making code changes as fast as possible and as a result be more effective when mitigating security issues.
Having said that, it is important that developers have Security in mind very early in the development process, writing Maintainable software in a way to minimize the impact of security events.
There are several ways to assess software Maintainability and all of them concern both Architectural and Code Quality aspects. In our practice at code4thought through our partnership with SIG we monitor systems of banking and telecommunications sectors in terms of software Maintainability and we, mainly, examine how decoupled an architecture can be and if we can identify patterns in source code such as Duplication and Code Complexity. In the following paragraphs, we are going to discuss how these aspects of software Maintainability can be intertwined with what we call Security by Design.
1. Centralized architecture
Centralized authentication and authorization controls are important as they follow the Open closed principle (SOLID) meaning that centralization prevents situations in which a change in one location also requires changes to other parts of the implementation.
Let’s have a look at a case where Spring Security implements the concept of centralized authorization.
Spring Security enables us to set up some basic configuration in a file e.g. SpringConfiguration.java as follows:

Apparently, we can centrally add role authentication in certain endpoints for http requests, such as checking if someone is Admin when hitting an endpoint containing the string “admin”.
Imagine now, what the risks would be if we should implement this check in every single http method with the aforementioned endpoints. Something could be omitted or, in case a change is required in functionality, the effort and time needed to implement and test it in all places would be greater, especially in the case of a new developer.
Therefore, it is always a good architectural decision to choose security frameworks in order to implement centralized mechanisms. What is more, maintaining the authentication and authorization mechanisms takes effort, expertise and responsibility to stay up to date with the current updates of the field. For example, basic security principles such as Deny by default can be easily applied. In the previous case, we can apply it using denyAll() method as seems below:
2. Duplication
One of the most common behaviors/practices that we identify in codebases is code duplication. Code blocks of identical implementations are found multiple times in the codebase decreasing the Maintainability of the system.
What exactly does this mean? Very often the need occurs for changes in the functionality. Having duplicates in the codebase makes it difficult to identify all the places where the change should be made, while the risk of omitting something is increased. It is not always possible to keep track of every duplicate. After having identified the places where to implement the change a developer should also proceed to the implementation, which demands extra effort to maintain all the code blocks adding time to test it and, eventually, time to market.
Adding the context of Security by Design, duplicate code means that security weaknesses or, even worse, vulnerabilities are spread around the codebase. What is more, all this extra effort needed to apply a fix, results in delays in mitigation of security issues which may constitute great cost, e.x. financial or in terms of sensitive information.
What else can go wrong? To have the illusion that you have fixed a vulnerability, however, having missed a spot and leaving the system wide open to more attacks.
In the following example there are several code blocks for encoding a password spread around the codebase.

What will happen if we need to upgrade to a safer encryption algorithm? Someone should locate all the places to make the fix while not being certain that nothing is missed.
What would solve the problem is to use a function that implements password encryption and can be called in all places where a password should be encrypted. In addition, in order to upgrade to a safer encryption algorithm, e.g. from DES to AES, this could be implemented only in one place, avoiding the extra effort and the risk of omitting some replacement.
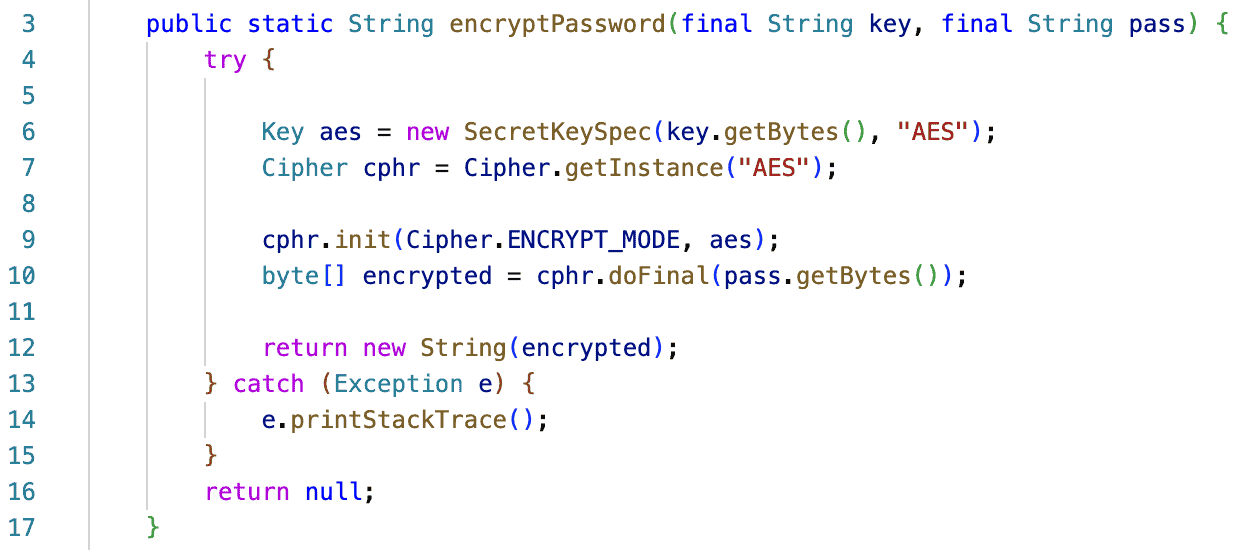
In order to tackle code Duplication, the implementations should be centralized and in reusable code blocks. This way, changes can be implemented in only one place making it easier to find, fix and test them.
3. Code complexity
Writing maintainable code means writing simple methods or functions. Avoiding complexity and keeping a low number of decision points makes the code easy to read and understand and more importantly easy to test. Therefore, more maintainable code in terms of complexity leads to less time to make changes with a minimized risk as it is easier to be tested.
All these code characteristics are important when it comes to methods or functions with authentication and authorization functionalities. Code must be readable and simple in order to avoid omitting checks, for example, when adding a new rule to check the updated password of a user.
The following example is a block of code regarding password handling with high complexity:

In addition, code complexity may lead to confusion and as a result to incorrect business logic.
But what does complexity actually mean for the job a developer has to do? Let’s have a look at how complex this function is by using McCabe complexity as a metric. McCabe or Cyclomatic complexity counts how many are the independent paths executed by the function. In our example, the function has 21 McCabe complexity. Having 21 different execution paths means that a developer should create 2^21 test cases, that is 2.097.152, to check for the validity of the functionality. Therefore, complex units take a lot of effort to be tested while sometimes testing them thoroughly may be impossible.
In the case of a security event, time will be spent to both analyze and test the code which can delay an important fix to mitigate the attack.
In the example that follows, it is not clear if an element should be read-only or not when the user is admin:
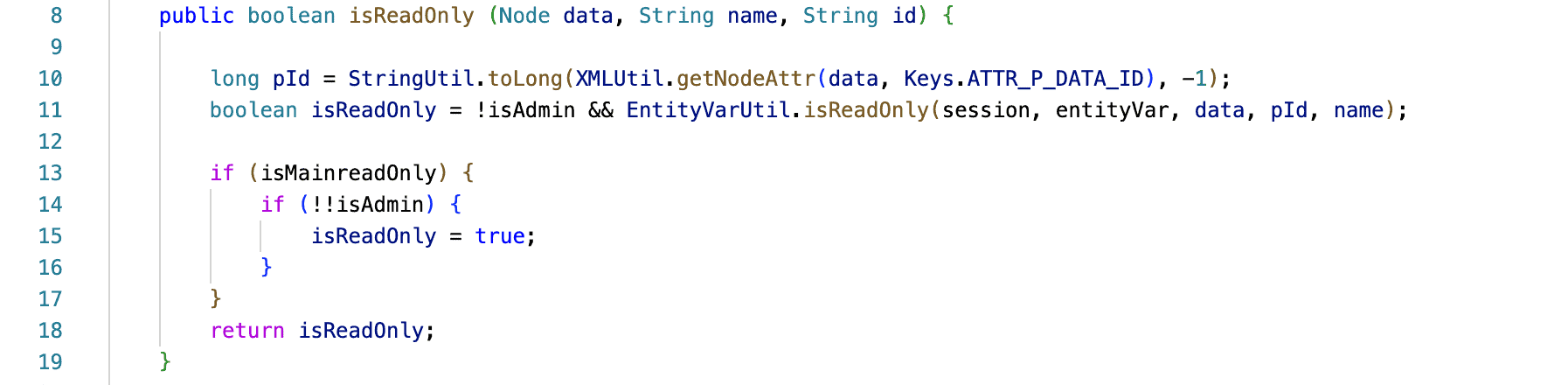
From another perspective, there is the concept of security through obscurity. More specifically, obscurity means that by adding complexity implementations which concern security become difficult to understand, hence safer from attacks. Additionally, another practice to obscure the code is renaming the variables to arbitrary names in order to make it less clear that the code refers, for example, to password validation.
However, this practice should be avoided. By obscuring the code, it takes more time to understand what it does. As a result, when a security issue occurs, more time will be consumed to understand the functionality, locate the bug and implement a fix as a response to a security attack. The amount of time spent can be crucial regarding the impact of the attack. What is more, arbitrary variable naming may lead to confusion which can result in the introduction of new bugs or the omission of an important implementation.
After all, security by obscurity is not a practice that we can solely rely on but it works complementary along with other practices.
4. Deprecated code
Deprecated code uses deprecated or obsolete functions, which suggests that the code has not been actively reviewed or maintained. The existence of deprecated code in the codebase can be misleading, adding effort to figure out why this part of code is kept in the codebase (is it still significant and why) or which version of the code should be used.
As a result, extra time is added to the development process with the risk of making a wrong decision.
Apart from the aspect of time, code hygiene is important for Security by Design. The codebase should be maintained to be clean. Why is this important? Let’s examine the case where a new developer joins a team and chooses to use a deprecated version of a function, missing for some reason that a newer version is currently used. If, for example, the function concerned the usage of a deprecated TLS version, this could lead to the introduction of a security weakness creating space for a security vulnerability leading to the compromise of network security.

The instance of TLS in use should be, for example, TLS 1.2 and the line 8 of code should be replaced with ‘context = SSLContext.getInstance(“TLSv1.2”)’ for secure communication.
The same could happen when keeping code which is used only on specific occasions, e.g during the development phase such as a hostname verifier that always returns true.

A common realization
An interesting realization is that MITRE’s CWE list includes bad coding practices such as ‘NULL Pointer Dereference’ or ‘Missing Default Case in Switch Statement’ as security weaknesses. What is indicated is that ‘the product has not been carefully developed or maintained. If a program is complex, difficult to maintain, not portable, or shows evidence of neglect, then there is a higher likelihood that weaknesses are buried in the code.’. About 60% of CWE’s list items do not refer to vulnerabilities per se but rather to coding practices, which proves the connection between Maintainability and Security by Design.
Conclusion
All the above lead to the conclusion that it is important for developers to be aware of secure coding best practices as early as possible in the development process. Therefore, awareness should be raised on how Software Maintainability and Security by Design are intertwined and affect each other. After all, maintainability means faster changes with less risk, a concept which is always important when dealing with security incidents.
1.Bijlsma, D., Ferreira, M. A., Luijten, B., & Visser, J. (2011). Faster issue resolution with higher technical quality of software. In Software Quality Journal (Vol. 20, Issue 2, pp. 265–285). Springer Science and Business Media LLC. https://doi.org/10.1007/s11219-011-9140-0