OWASP Top 10 Vulnerabilities for Large Language Models (LLM): Impact and Mitigation

30/07/2024
14 MIN READ /
Large Language Models (LLMs) have garnered significant attention since the mass-market introduction
of pre-trained chatbots in late 2022. Companies keen to take advantage of LLMs quickly incorporate
them into their services and processes. However, the high speed of LLMs’ development leaves security
measures behind, thus making many applications open to high risks.
In response, a multinational team from diverse backgrounds contributed their collective experience to create the OWASP Top 10 for LLM Applications list: a critical guide to assist developers and security experts by offering practical, actionable, and concise security guidance to navigate the complex and evolving terrain of LLM security.
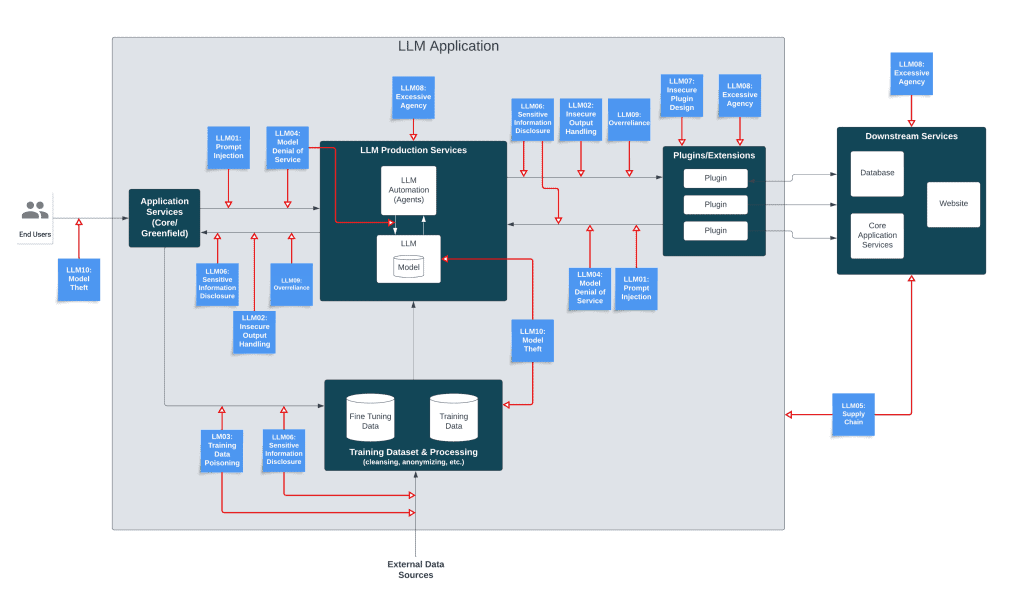
The Top 10 List: Impact and Mitigation
LLM01 Prompt Injection
Impact: A prompt injection attack can modify LLM applications by overwriting system prompts or affecting external inputs to perform unwanted operations, leak sensitive data, or compromise application security.
Mitigation: Validate and sanitize input to avoid prompt injection. All user inputs should be screened for fraud and removed. Predefined prompt templates with specified variables limit user inputs and reduce insertion risk. Regularly updating and analyzing the model’s training data and prompts help prevent exploitation by outdated or vulnerable prompts, while monitoring and anomaly detection systems can address suspicious activities in real time.
LLM02 Insecure Output Handling
Impact: Accepting and processing model findings without inspection makes LLM applications vulnerable to insecure output handling. This vulnerability can cause Cross-Site Scripting (XSS), Cross-Site Request Forgery (CSRF), Server-Side Request Forgery (SSRF), privilege escalation, and remote code execution. Bad actors can exploit LLM flaws with malicious inputs, compromising backend systems and sensitive data.
Mitigation: Validating and sanitizing output reduces the risk of insecure output handling. As with inputs, LLM outputs should be verified for malicious code or commands. Strong Content Security Policies (CSP) help stop dangerous scripts in web apps. Secure coding that automatically validates outputs lessens risks, while regular audits and pen tests discover and address output processing vulnerabilities.
LLM03 Training Data Poisoning
Impact: Tampered training data for LLMs might introduce flaws or biases that affect the model’s security, effectiveness, and posture. Cybercriminals can inject harmful data to distort model outputs and behaviors, making the model vulnerable and exploitable.
Mitigation: Training data poisoning requires a multifaceted approach. Firstly, reliable data sources lessen the risk. Robust data validation and filtering can discover and remove fraudulent or biased data before it is used for training. Updating training datasets quickly identifies and fixes corrupted data. Anomaly detection systems can also find model behavior patterns that may suggest poisoning. Sharing best practices and threat intelligence improves LLM training data security and reliability.
LLM04 Model Denial of Service
Impact: Attackers use LLMs to undertake resource-intensive tasks, degrading service or increasing operating costs. This vulnerability is exacerbated by the unpredictability of user inputs, which can be crafted to consume excessive computational resources or even cause complete outages.
Mitigation: A well-equipped defensive toolbox against Model DoS includes rate restriction and throttling, limiting requests, and computing resources per user or session. Anomaly detection systems can also respond to DoS attack patterns. Load balancing and auto scaling techniques can help distribute the computational load and maintain service availability during peak demands. Regularly reviewing and optimizing the model’s architecture can also improve DoS resilience.
LLM05 Supply Chain Vulnerabilities
Impact: Insecure components or services disrupt LLM application lifecycles, creating supply chain risks. Third-party datasets, pre-trained models, and plugins pose security risks if overlooked. Attackers can access, modify, or interrupt services using malware and software vulnerabilities.
Mitigation: Third-party components and services in LLM applications must be thoroughly vetted and monitored to mitigate risk. Security evaluations and audits uncover hazards, and software patches and updates resolve vulnerabilities. A strong security policy can also manage risks using secure coding practices, dependency management tools, and automated security scanning. Working with trusted vendors can further improve LLM application lifecycle security.
LLM06 Sensitive Information Disclosure
Impact: LLM applications can leak sensitive data. The model may accidentally expose confidential data in its responses, resulting in unauthorized data access, privacy issues, and security breaches.
Mitigation: Use tight data sanitization and user policies to protect from data disclosures. Check training data for sensitive information. Data masking and anonymization prevent accidental disclosure. Strict access controls and user authentication mechanisms can further restrict sensitive data access. Audits and monitoring of the LLM’s outputs can assist in detecting and correcting any disclosures promptly, maintaining data confidentiality and security.
LLM07 Insecure Plugin Design
Impact: LLM applications’ plugins may have insecure inputs and insufficient access control. Insecure plugins can be exploited, compromising the entire system and allowing data breaches and disruptions.
Mitigation: Strong input and access control reduce plugin vulnerabilities. Sanitize plugin inputs to prevent code injection. Implement stringent access controls to prevent exploitation. Plugin security audits and code reviews provide early warning and healing. Finally, secure code and security frameworks can make plugins more resilient.
LLM08 Excessive Agency
Impact: LLM-based systems with too much authorization or autonomy may act unintentionally and harmfully. The model’s autonomy might result in unplanned data tampering, security breaches, and operational disruptions.
Mitigation: The functionality, authority, and autonomy of an LLM-based system should be limited to reduce excessive agency. Strict access control limits system capacity and enforces boundaries and permissions. Effective monitoring and auditing tools can follow system activity and identify deviations. Well-defined operating restrictions and fail-safes can prevent unexpected system actions.
LLM09 Overreliance
Impact: LLM overreliance arises when systems or individuals rely on these models without appropriate oversight. Due to their inherent limitations and training data quality, LLMs can produce improper content, which can cause misinformation, legal issues, and security risks.
Mitigation: Comprehensive management and verification help reduce LLM overreliance. Human-in-the-loop (HITL) systems can assure LLM output correctness and suitability. Avoid misuse of LLM-generated content with clear standards. Continuous user training and education regarding LLMs might also encourage a caution culture, while regular model and training data updates and inspections can further improve reliability.
LLM10 Model Theft
Impact: Model theft involves the unauthorized exploitation of proprietary LLM models. This can lead to significant economic losses, as stolen models can compromise a company’s competitive advantage, allowing competitors to use or modify the models “on the house” without incurring development costs. Model theft compromises privacy and security by exposing model data.
Mitigation: To prevent model theft, use tight security throughout its lifecycle. Encryption of model files and data at rest prevents unauthorized access. Multi-factor authentication (MFA) and role-based access control (RBAC) ensure accessibility. Moreover, audits can detect theft attempts, while secure development practices and continuous security assessments further enhance protection.
LLM App vs. Web App Security
LLM vulnerabilities differ from traditional web app vulnerabilities due to the dynamic and data-driven nature of AI/ML models. AI-specific issues introduce unique challenges as models can inadvertently make autonomous decisions or reveal sensitive information based on their training. Unlike static code vulnerabilities in web apps, LLM vulnerabilities often stem from the complexity of data inputs and model behaviors, necessitating specialized mitigation strategies that go beyond traditional security measures.
Developers, data scientists, and security experts can better protect their systems and data by understanding and adequately addressing these vulnerabilities. LLM app and AI security and trustworthiness start with transparent and secure-by-design systems to ensure controllability, reduced risks, and enhanced business outcomes.