5 principles on building
trustworthy
and reliable ML products


In the last decade Artificial Intelligence (AI) systems went from notebooks-to-play-with to Production-ready and large-scale products or applications. The establishment of DevOps practices was necessary for the continuous integration and deployment of a software product, but it was not enough especially for the AI-based systems. In this particular domain of software systems there are 2 key aspects that do not exist in traditional software: The Data and the Model.
This has led researchers and engineers who are involved in all phases of a ML product lifecycle to define a new term called MLOps (Machine Learning Operations). The term “Ops” refers to “operationalize” which means bringing machine learning systems into Production.
As seen in Figure 1, AI Adoption by organizations has been significantly increased globally in 2021. Thus, it is more important than ever to ensure that MLOps processes run smoothly and their products are reliable and trustworthy.
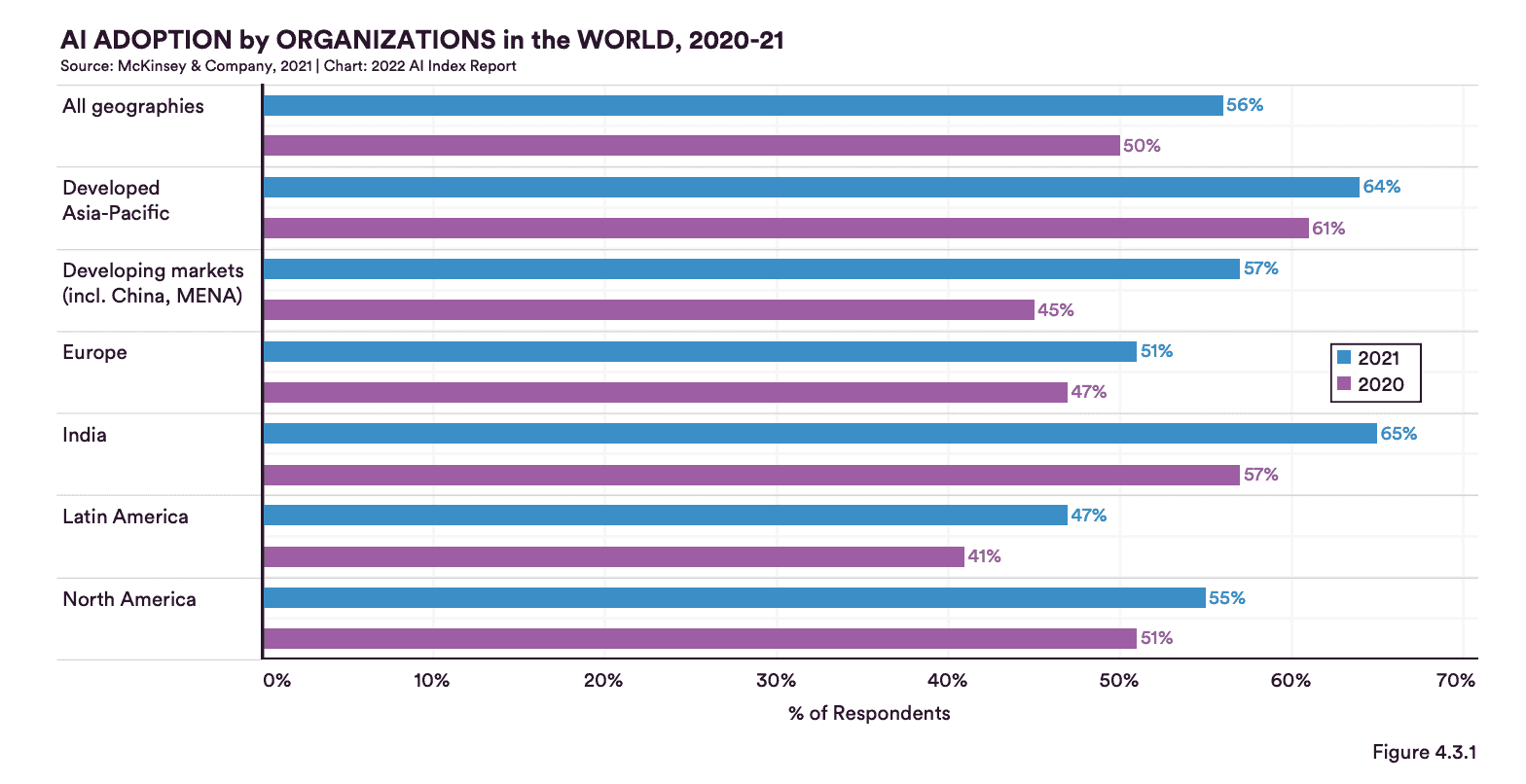
Figure 1: AI Adoption by organizations in the world 2020-2021 (Source: Stanford AI Index Report 2022)
In this article, we will present 5 principles that are highly recommended for smooth and reliable MLOps processes.
“A principle is viewed as a general or basic truth, a value, or a guide for behavior. In the context of MLOps, a principle is a guide to how things should be realized in MLOps and is closely related to the term “best practices” from the professional sector. “ 1
MLOps Basic Principles
1. Continuous…
Integration/Delivery (CI/CD)
Automated CI/CD of the pipeline includes tasks for building, testing and validating data, models and components of the ML pipeline and the deployment of the model artifact into production.
ML training & evaluation
After deployment to production, model performance decays over time, most commonly because of concept or data drift, as data changes rapidly in the real world nowadays. Continuous ML training & evaluation should be applied, as depicted in Figure 2.
At first, new data arrives to the system, usually from user input in an application. Then, engineers need to select a specific subset to be used as input to the ML algorithm for training the model. The retraining trigger is pulled when a shift in model performance is identified, either by an expert or automatically. When the trigger is pulled, the new data is being prepared for training (feature engineering). The next step is to validate and test the output of the model by domain experts (offline testing). Offline testing can lead to either retraining of the model if the quality standards are not met, or to deployment to production. After deployment to production continuous testing, usually A/B testing, is performed to detect potential performance issues.
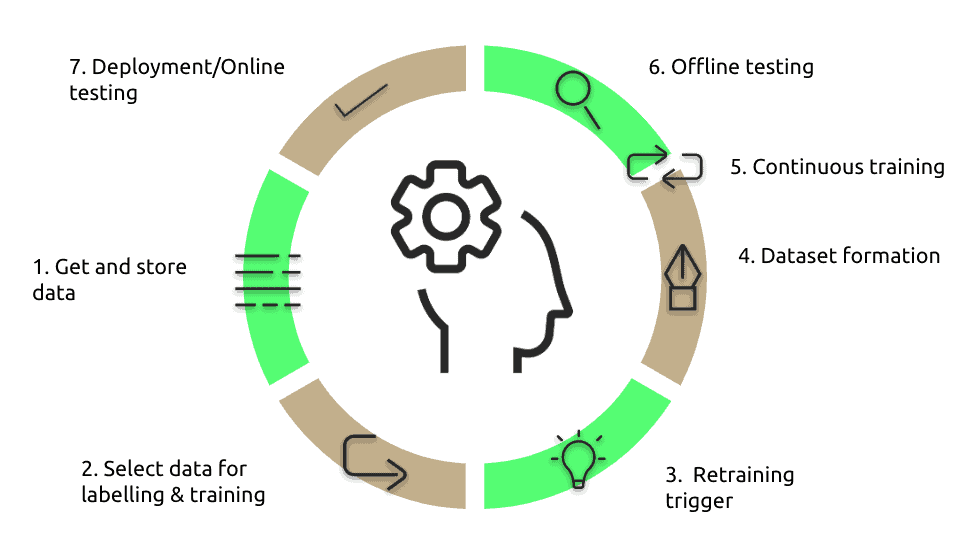
Figure 2: MLOps lifecycle
Monitoring
1. Monitoring the health of the system, using metrics like CPU/GPU utilization, throughput and memory utilization. Any issue in the performance of our system or any outage can be really costly.
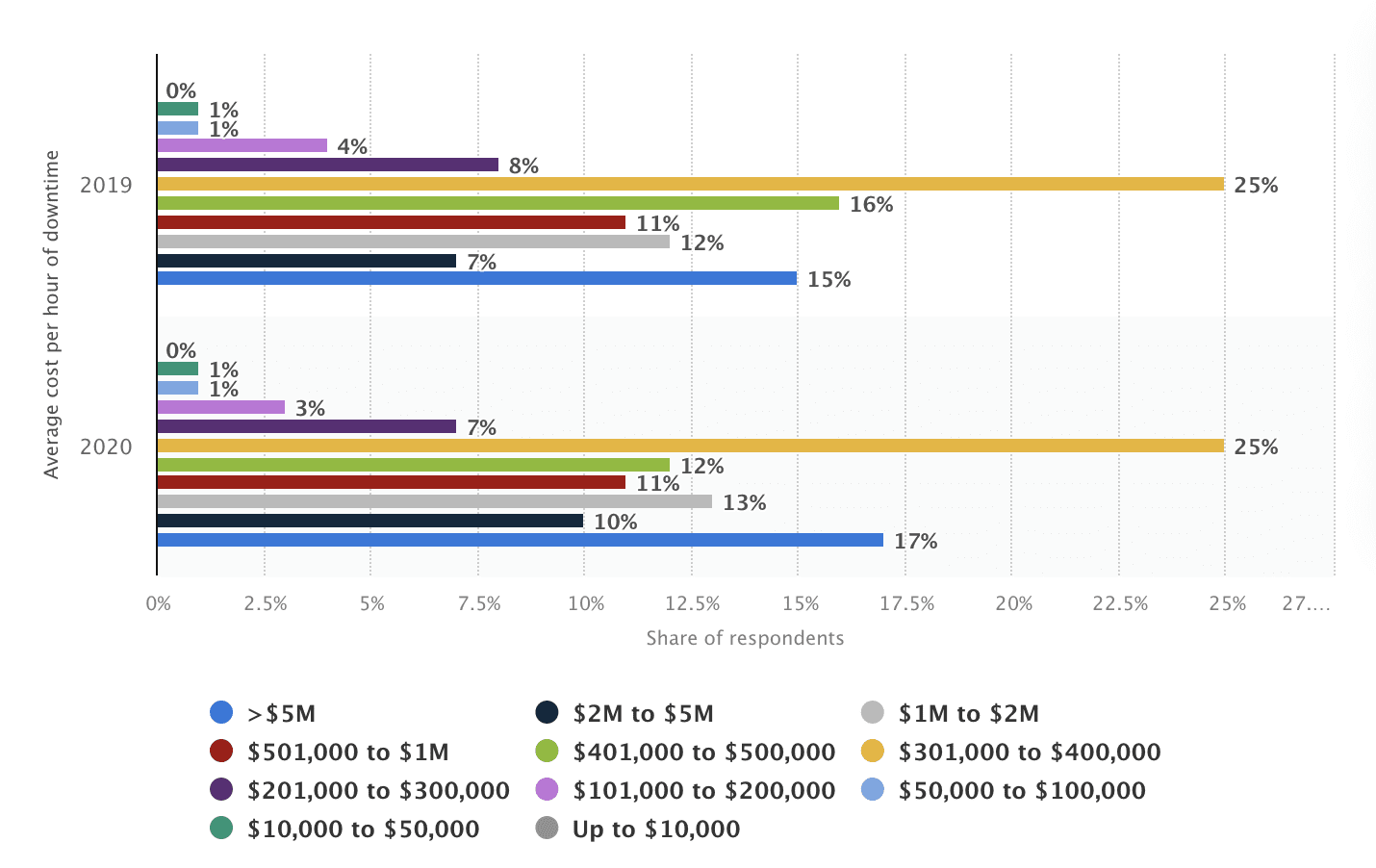
Figure 3: Average cost per hour of enterprise server downtime worldwide (Source: Statista)
2. Monitoring the data and features for concept drift. Concept drift is the case where data in production do not match the schema which has been defined during the training step.
3. Monitoring the model to quickly identify potential decay in performance, which might be a sign that our model needs re-training.
4. Monitor for dependency changes caused by things like dependency updates.
2. Workflow orchestration
AI systems can get really complex.Graphs showing the order of execution of tasks in the ML workflow have become a necessity. Workflow orchestration tools not only help us identify the relationships of the different MLOps components, but also resolve dependency issues and identify and trace tasks that have failed, at no time. The most common type of graphs used in MLOps are DAGs (Directed Acyclic Graphs), like the one presented in Figure 4.
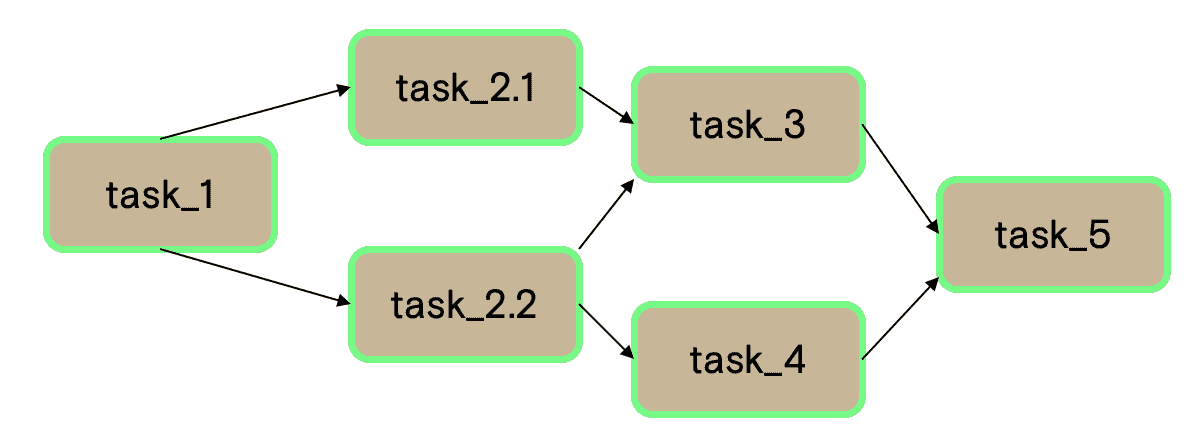
Figure 4: An example of a DAG
3. Versioning
In traditional software systems code versioning is solely needed, so as to allow multiple people to work simultaneously on the same codebase, without conflicts. In AI-based systems it is essential not only the versioning of their source code, but the versioning of data and the model too. A new version of a model is usually created even for the slightest change in the value of a hyperparameter or a parameter or of the features provided as input for its training. Data versioning includes keeping track of different versions of data metadata, datasets and features.
MLOps caters for a continuous experimental process and thus versioning plays a vital role to the whole process. It allows us to rollback quickly to a previous version, either in case something goes wrong or if we want to test another implementation of a model or previous set of features based on a client demand.
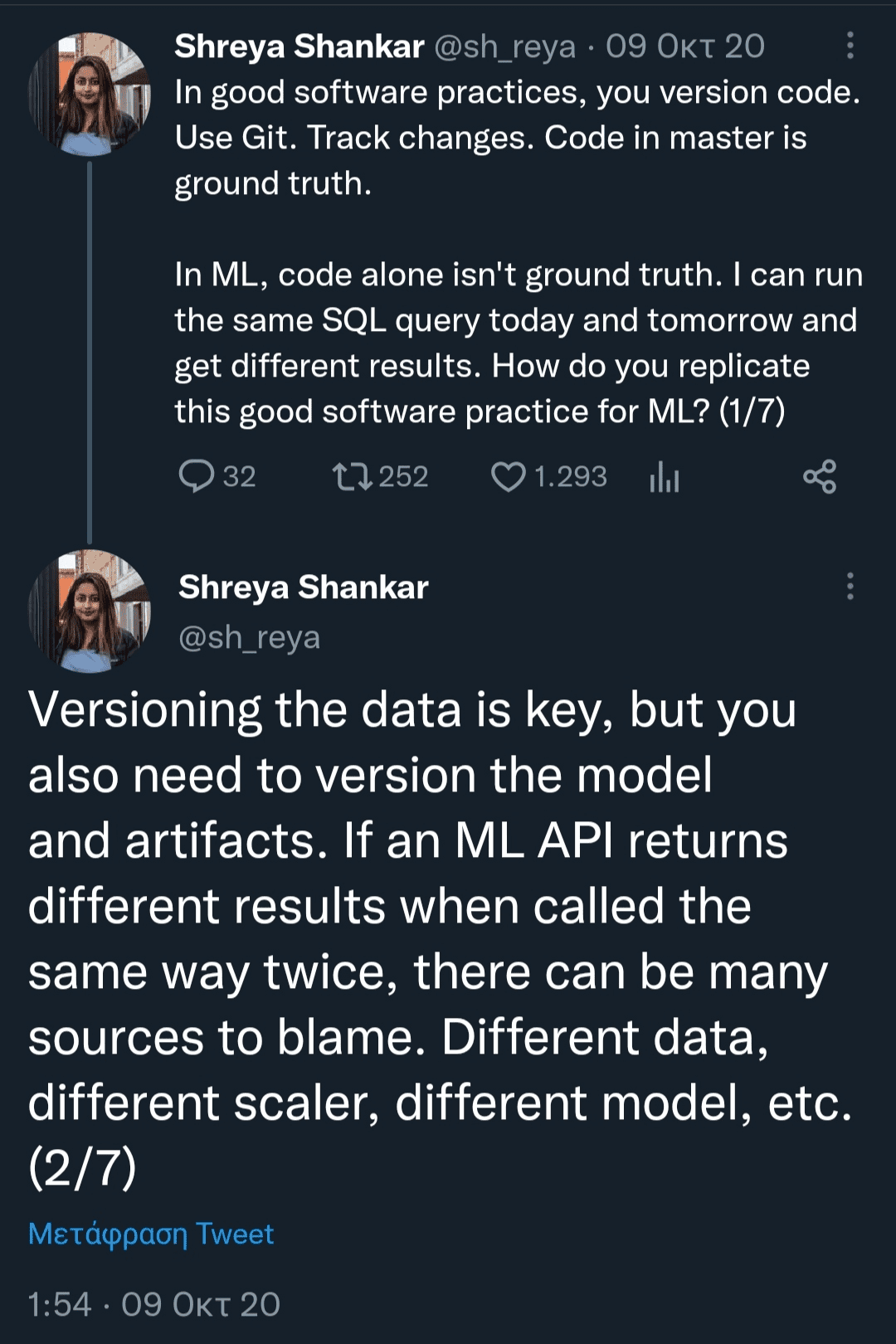
Figure 5
4. Collaboration
Building and deploying an ML system to Production usually requires teams composed of people with different backgrounds, knowledge and expertise. In a typical MLOps process Data Scientists/Engineers, DevOps Engineers, Software Engineers, ML Engineers, Business stakeholders and Domain Experts are involved. The effective communication and collaboration between all members of a team and across teams can increase productivity, reduce time spent in issue handling and of course help people enjoy their work at the highest level.
5. Tracking/logging of ML metadata
In every step of an MLOps workflow a vast amount of information and data is produced. To keep track of meta-information about all this data, besides versioning, tracking and logging of this metadata is essential. But what type of metadata are usually stored?
- Artifact-related metadata such as version, creation date, author and reference,data schema and data structure of the Data-artifact
- Execution/code-related metadata such as commit-hash, environment configuration etc.
- ML Experiment metadata
Multiple experiments are being executed/conducted and ML metadata needs to be tracked for future reference.
Benefits
But what are the main benefits of adopting these principles for a ML team?
Reproducibility
Reproducibility refers to obtaining the exact same result every time we run a ML task and/or experiment. All the above-mentioned principles are highly recommended for increasing this aspect. Ensuring reproducibility is one of the top requirements in MLOps as it increases productivity and it significantly reduces the time spent in ML experiments and research. It also helps auditing and testing a given ML model in a more efficient way. Therefore costs are significantly reduced, as training a new ML model can be really expensive.
Scalability
Adopting these principles results in scalability, as ML models and data can grow significantly over time.
Maintainability
Tracking and logging ML metadata, versioning and monitoring can provide a significant boost in maintainability, as errors are more easily detected and all the appropriate information to solve them is available.
In conclusion, the rapid growth in AI adoption and the impact that has in society makes adoption of good practices in building and operating AI systems a necessity.
Adopting best practices, not only helps teams increase the reproducibility, scalability and maintainability of their systems but it also enables compliance with existing and upcoming standards and regulations such as the EU AI Act that is expected to be finalized this year, UK’s framework for AI Regulation and the Blueprint For An AI Bill Of Rights in the USA.
References: